



Data Science With Python Tutorial for beginners and professional
When it comes to data science application, it gives an extensive library to bargain with and not suggest to this is open source, interpreted high-level tools. Some programming languages exist in the mind of data science. Python is one the best certain language. That its necessary component for data science plus vice versa. That is introduced by learning scientific computing and added numpy.
Python is a common-goal programming language, that is growing more and more famous for creating data science. Unlike some other Python tutorial, that program focuses on Python especially for data science. So the most considerable, Python is extensively used in the scientific and research summation because this is easy to use has very easy syntax that makes a very simple adapt for people who don’t have a software engineer background. Exact data sure of that as well.
So in the year of 2018, 68% of data scientists announced using python regular making it the numeric one tool for analytics professionals. I think maybe this deal will certainly regularly to evolve. if you have dreamed about data science then you can learn a lot of data science, so that time to jump in data science with python.
Python Basics
So in this topic, you learn about some basics of python and you will write your first program. The most simplistic directive a language construct that defines how a compiler should treat its input in Python is the “print” directive that easily prints out a line also adds a newline, unlike in C. To print a string in Python.
Python 2.7 vs 3.4
That is one of the most debated questions in Data Science with Python. You will regularly join tracks by it, especially if you are a trainee. There is no right/wrong decision here. That completely depends on this situation and you require to use it. We will attempt to provide you some pointers to support you create an educated choice.
Python 2.7
Excellent community assistance! That is something demand in your start days. Python 2 release in the new 2000 and has been in use for higher than 15 years.
The plethora of triple-party libraries! Though various libraries have given 3.x support still a huge number of modules run only on 2.x versions. If you propose to use Python for particular applications like web-development with a large dependence on outside modules, you force be better off among 2.7.
Amazing of the features of 3.x versions have backward adaptability and tin work with 2.7 version.
Python 3.4
Cleaner and more active! Python developers must fix any inherent glitches including trivial checks in position to set a more substantial company for the future. That strength not be very significant initially but will matter ultimately.
That is the future! 2.7 is the latest release for the 2.x family and finally, everyone ought to shift to 3.x versions. Python 3 has published stable versions for the past 5 years and will remain the same.
Python Installation
We have 2 ways to install Python:
- first You can download the Python directly from the project site and install unique elements and libraries you desire
- Alternately, and you also can download plus install a package, which begins with pre-installed
libraries. I would suggest downloading Anaconda. A different option could be Enthought Canopy Express.
First program example
Print (“that line will be print”)
So use the “print” command to print the line “Hello world”
Print(“Hello world”)
Hello world
Python Data Structures
So in python, they are the following data structures, lists, tuple, dictionaries. set also available only in python 2.5 old versions so the list is like 1d arrays but you can also create a list of other lists and take a multidimensional array. A data structure fundamentally just says that they are a structure that can be data concurrently, in other words, say it raises a collection of relevant data. And the completed-in data structure in python language Tuple, Dictionary list, set, string so we will learn how to use each of them.
Tuple
A tuple is immutable in nature collection of heterogeneous data types. It is only read data types. It is using to be together many things. Study of them as related to lists but out the extensive functionality, the class of the list provides you. one important feature of tuples is that they are immutable nature like as str then you can’t changed tuple.
Tuples are defined with special parts ordered by commas by an elective pair of parentheses,
Tuples are usually in cases where a statement or a user-defined function can securely assume that the collection od values if tuple values use then will no change the value.
x=(1,2,” ABC” , 7.5)
x[0]=gx
If covert in list
y=list(x)
x=input…”7.5” (come to str)
Int(x) error.
Example
this tuple = (” grapes”, “banana”, “mango”)
Print(this tuple)
Output = (‘grapes’, ‘banana’, ‘mango’)
Dictionary
Dictionary is a collection of key pair values. It is mutable in nature. The dictionary is like address books so you can find the address or contact details of any person with understanding only his/her name. we connect the keys name by value details. also, you remember the key is different only like you can not find out of the wrong information. And if u have tow persons with the same name.
Point be recorded you can use only immutable things like str for the keys of dictionary then you can use another immutable or mutable objects for the values of the dictionary so the basically says you can use the only easy object for keys
[keys] [values]
x={1: “ABC”, 9.77, “QPR”: 82, “ABC”: “QPR”: 77}
x.[“QPR”]-82
x[g]=55
X[0]-x index position , not access is only 1 to access
- Index element passed
Xfind()> find index method
*keys change id, change mobile number
Example of dict:
This dict = {
“brand”: “Honda”,
“model”: “City”,
“year”: 1995
}
print(this dict)
Output = {‘brand’: ‘Honda’, ‘model’: ‘city’, ‘year’: 1965}
List
The list is a data structure in python so this is a mutable nature and changeable ordered series of parts. Every part of the value that is inside from the list is called an item, just as strings are defined as characters between quotes lists are defined with having a value between square brackets []
so here is the example of a list
x =[1,2,9,7,5]
x[0]= “hello”
x[1]= 82
Example:
this list = [” grapes”, “banana”, “mango”]
Print(this list)
Output = [‘grapes’, ‘banana’, ‘mango’]
Set
Set in an unordered collection of easy things. that is used when the existence of a thing in a collection is more relevant than the order or how multiple times it occurs using sets. you can inquire for membership whether that is a subset of different find the intersection in two sets and so on,
example :
this set = {“apple”, “banana”, “cherry”}
print(this set)
Output = {‘apple’, ‘banana’, ‘cherry’}
String
Strings are created using single quotes or double quotes or also triple quotes. String in single quotes cannot exist any other single-quoted role in it unless an error occurs because the compiler won’t remember where to begin and end the string. To overcome this error, the advantage of double quotes is favored, because that helps in the production of Strings with single quotes in them. As strings that include Double quoted words in them, that use of triple quotes is recommended. Along with the triple quotes further, allow the creation of multiline strings.
Example of strings:
You can use single quotes or double quotes
| print(“Hello”) print(‘Hello’) Output = Hello Hello |
Python Iteration and Conditional Constructs
Like most maximum languages, Python also holds a FOR-loop which is the usual extensively accepted method for iteration. That has an easy syntax:
| for i in [Python Iterable]: expression(i) |
Hither “Python Iterable” container be a list, tuple or other excellent data structures that we will examine in the following divisions. Let’s get a peek at a simple example, learning the factorial of a number.
| fact=1 for i in range(1, N+1): fact *= i |
Proceeding to conditional statements, those are applied to execute code particles based upon a condition. The several regularly used construct is if-else, by the next syntax:
| if [condition]: __execution if true__ else: __execution if false__ |
During instance, if we desire to print whether that number N is even or odd:
| if N%2 == 0: print (‘Even’) else: print (‘Odd’) |
Python Libraries For Data Science
Python language is previously helping developers in creating standalone, PC games, mobile phones, and different applications. So the python with higher than 137,000 libraries supports in different ways. In that data-centric world where customers require relevant data in their buying journey companies also need data scientists to avail important insights by processing huge data sets.
This information leads you in important decision making streamlining business operations including thousands of different duties in which demand relevant information to perform efficiently. Therefore with the improved demand for data science, trainees and professionals are watching for sources to learn. one can go for Simplilearn’s online data science certification training, blog, videos and other resources that are available across the internet. Once they recognize how to deal with this unstructured information they are good to grab millions of flowing moments.
so here is given and discussing of some python libreries
Import math as m
From math import *
1. Numpy
Numpy is the first choice among developers who are don’t know about the technologies in which are bargaining with oriented material. That is a python package available for producing scientific computations and this is recorded under the BSD license.
In NumPy, you can leverage n-dimensional array objects, C, C++, Fortran application based union tools, functions for producing complex mathematical methods like Fourier transform, linear algebra, random number, etc. One can also use NumPy as a multi-dimensional package to handle generic data. Thus, you can efficiently combine your database by picking types of operations to work with.
NumPy is installed below the TensorFlow and other complex machine learning programs allowing their operations internally. Considering it is an Array interface, it provides us various choices to reshape large datasets. That can be used for generating images, sound wave representation, including several binary operations.if you recently register your presence in this data science or ML field, you must have an excellent knowledge of NumPy to prepare your real-world data sets.
Example of numpy zero
| import numpy as np np.zeros((4,4)) Output array([[0., 0.], [0., 0.]]) |
2. Keras
Keras is the most strong python libraries in which enables a higher level of neural networks and APIs for combinations. Those APIs executes the above top of TensorFlow Theano and CNTK. Keras is designed for reducing difficulties faced in complex analysis permitting them to calculate faster for one who is deep learning libreries for their work Keras is the best option.
That enables fast prototyping, helps recurrent including convolution networks independently and more their combination, execution across GPU and CPU.
Keras gives a user-friendly environment decreasing your stress in cognitive weight with simple APIs providing us the demanded results. Due to its modular characteristics, one can use categories of modules of neural layers, optimizers, activation functions, etc, for developing a new model.
That is an open-source library composed in Python. During data scientists having difficulty attaching new modules, Keras is a great option wherever they can easily attach a new module as classes and functions.
3. SciPy
Scipy is a different library function for researchers, developers and data scientists so don’t get distracted with the Scipy stack and library. That gives statistics optimization combination and linear algebra packages for computation. this is based on a numpy concept to handle by complex scientific problems.
That gives numerical methods for optimization and synthesis. That inherits qualities of sub-modules to collect from. If you have recently begun your data science profession, SciPy can be extremely important to guide you complete the whole mathematical computations thing.
We can understand how Python programming is supporting data scientists in crunching and analyzing massive and unstructured data sets. Different libraries similar to TensorFlow, SciKit-Learn, Eli5 are further available to support them during this journey.
4. Pandas
Involved as data science with python Data Analysis Library. PANDAS is a different open-source Python library for availing high-performance data structures and analysis tools. That is developed over the Numpy package. This includes DataFrame as its main data structure.
By DataFrame you can collect and maintain data of tables by performing manipulation across rows and columns. Techniques like square bracket symbols decrease a person’s effort in data analysis responsibilities like square bracket symbols. Here, you will receive tools for obtaining data in-memory data structures implementing read and write responsibilities even if they are in various forms such as CSV, SQL, HDFS or excel, etc.
5. SciKit-Learn
SciKit-Learn is an accessible tool for DA and mining-related tasks. this is free sources and licensed under the BSD. anywhere can access or reuse it in various contexts. Scikit is developers over the numpy, Scipy, and mataplotlib.this is being applied for classification and clustering o handle spam, image recognition, drug reply, stock pricing, customer segmentation, etc. this also provides dimensionality compression, model selection, and pre-processing
6. Matplotlib
That is 2d plotting library of python and this is very popular with data scientists for designing different figures in many formats in which are agreeable crossed their appreciated platforms. And we can simply do that in their data science with python code, Ipython shells or Jupyter notebooks, application servers. with Mataplotlib and after you can make histograms plots, bar charts, scatter plots, etc.
7. Seaborn
Seaborn did design to imagine the multiple statistical models. That holds the potential to perform proper charts such as heat maps. Seaborn did create on the idea of Matplotlib and anyhow that is higher dependent on that. Minor to minor data categorizes can be simply imagined by that library in which is why this should become familiar with data scientists and developers.
8. Theano
Theano is an open-source project issued below the BSD permit and was developed with the LISA, momentarily MILA collection to the University of Montreal, Quebec, Canada home of Yoshua Bengio. That is called after a Greek mathematician.
Theano is a compiler for statistical characters in data science with python. That understands how to take your structures and convert them into very effective code that practices NumPy, experienced native libraries like BLAS and native code C to run as quick as possible on CPUs or GPUs.
That is using a host of original code optimizations to remove as much representation as attainable from your hardware. If you are within the nitty-gritty of mathematical optimizations in code, hold out this impressive list.
The exact syntax of Theano expressions is representative, which can imply off-putting to trainees applied to common software development. Specifically, the expression is described in the conceptual understanding, compiled and next really used to make predictions.
That was specially designed to manage the types of computation needed for deep neural network algorithms applied in Deep Learning. That was 1 of the first libraries of its kind development started in 2007 and is deemed an enterprise pattern for Deep Learning analysis and development.
9. Tensorflow
That open-source library obtained designed through Google to compute data low charts with the allowed machine learning algorithms. That was designed to satisfy the high requirement for the practice of neural networks operates. This is not just restricted to the scientific computations implemented by Google rater that is publicly implying used in the traditional real-world application.
Due to its tremendous production and extensible architecture, the deployment for all CPUs, GPUs or TPUs enhances simple task operating PC server clustering to the end devices.
Some additional libraries maybe you need
OS for Operating system and file actions
network x and graph for graph-based data manipulations
general expressions for detecting models in text data
Beautiful Soup for scrapping web. That is secondary to Scrapy since it orders selection information of just a single webpage in a run.
Forthwith that we are intimate with Python fundamentals and added libraries, let us take a deep dive into problem-solving for Python. Yes, I suggest creating a predictive model! In the method, we apply some important libraries and also come over the next level of data structures. We will guide you by the 3 key phases:
| Data Exploration | finding out further about the data we hold |
| Data Munging | cleaning the data and performing by it to perform it rightly suit statistical modeling. |
| Predictive Modeling | moving the actual algorithms and should fun. |
Exploratory Data Analysis Python
Within order to investigate our data more, let me propose you to the different animal as if Python not to enough. Pandas is 1 of the several useful data analysis library in Python we know those names reflect weird. They have been instrumental in developing the use of data science with python in the data science community. We will instantly apply Pandas to read a data set of a performs exploratory analysis including making our first basic categorization algorithm for determining this problem. Before loading the data, let’s know the 2 key data structures in Pandas Series and DataFrames.
Series and Dataframes
Series can be assumed as a 1 dimensional labeled/ recorded array. You can obtain particular components of this series into those labels.
A data frame is comparable to an Excel workbook. You have column names leading to columns and you have rows, That can be obtained by the aid of row numbers. The quintessential variation being this column names and row numbers are identified as column and row table, in case of data frames.
Series and data frames perform the kernel data model to Pandas in data science with python. The data sets are beginning to understand into these dataframes moreover suddenly different methods e.g. group by, aggregation, etc. can be implemented very simply to its columns.
For Example loan Prediction Dataset
| Variebale | description |
| Loan id | Unique loan id |
| Gender | male/female |
| Married | Applicant married (Y/N) |
| Dependents | Number of dependents |
| Education | Applicant Education (Graduate/ Under Graduate) |
| Self_Employed | Self-employedY/N) |
| ApplicantIncome | Applicant income |
| CoapplicantIncome | Coapplicant income |
| LoanAmount | Loan amount in thousands |
| Loan_Amount_Term | Term of the loan in months |
| Credit_History | credit history meets guidelines |
| Property_Area | Urban/ Semi-UrbanRural |
| Loan_Status | Loan approved (Y/N) |
let’s start with the exploration
To begin, start Python interface inline and Pylab style with typing on your computer/ command prompt.

That unlocks up an iPython notebook in the Pylab environment, which has a few beneficial libraries previously imported. Furthermore, you will be ready to plot your data inline, which operates an extraordinarily safe environment for interactive data analysis. And You can verify whether the environment has arranged accurately, by keyboarding the following command and arranging the output as discussed in the figure below.
![]()
I m working on windows, and I have sorted datasets in these following locations.
Importing libreries and data set
We will use these libraries for this tutorial.
Numpy
Panda
Matplotlib
After importing the library, you examine the dataset applying function read_csv(). That is how the code looks until that stage:

Data Exploration
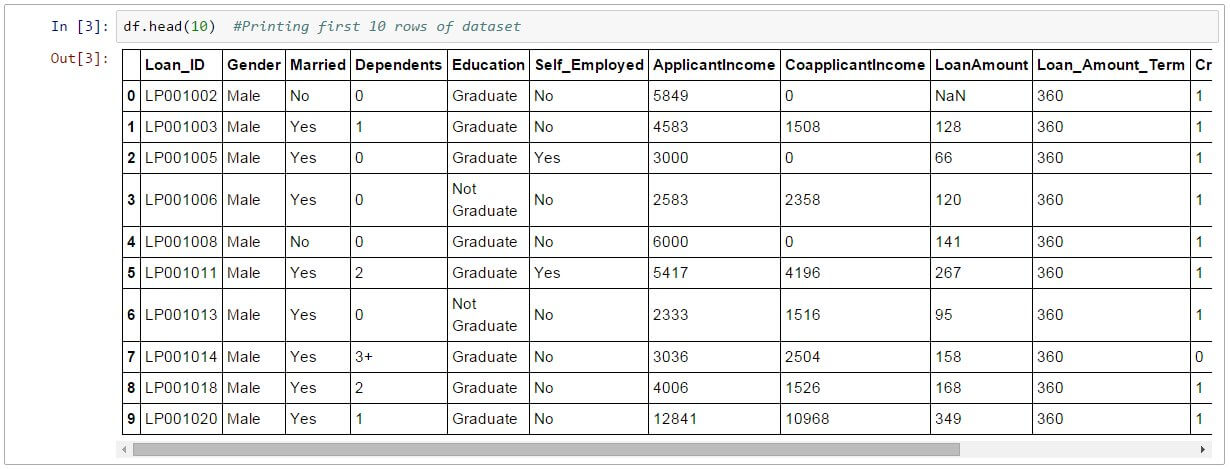
So one time you have read data set and you can have look top few rows using the function head()
df.head(10)
Following, you can view at the summary of numerical ranges by applying define() function
df.describe()
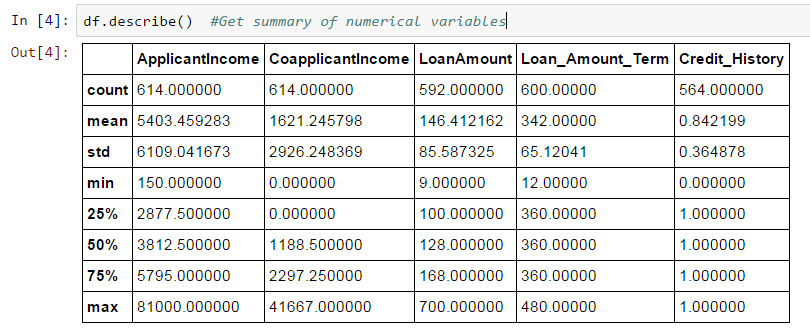
To describe() the function and would present, and standard deviation(std), min and max in that output.
so we have few interfaces so we can represent a looking output of the defined() function.
- loan amount 615-592, 22 values missing
- loan term 614-600, 14 values missing
- credit history have 614-564, 50 values missing
- So we all also see about the 84% customer have a credit previous record.how? So is that mean of credit
field is 0.84 so you get credit previous record have value 1 for certain these who have a credit history and 0 otherwise
- The customer income arrangement seems to be in line with expectations. And some by co customer income.
for the non-numerical conditions, for example, arm area, credit history, etc, so we can see on frequency assignment to know whether and that makes the sense or not. so the frequency table can be print with the following command.
df[‘Property_Area’].value_counts()
Distribution Analysis
Presently that we are intimate with primary data features, let us consider the distribution of several variables. Let us begin with numeric variables – namely Customer income and LoanAmount
Let’s begin by plotting the histogram of Customer income using the next commands:
![]()
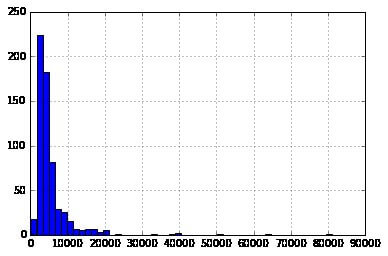
Here we perceive that there exist few absolute values. That is to the cause why 50 cases are needed to depict the distribution certainly.
Following, we see at box plots to explain the distributions. Box plot for fare can be plotted by: Here we perceive that there exist few absolute values. That is to the cause why 50 cases are needed to depict the distribution certainly.
Following, we see at box plots to explain the distributions. Box plot for fare can be plotted by:
df.boxplot(column=’ApplicantIncome’)
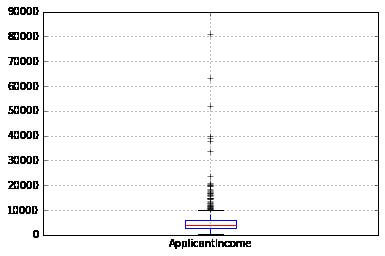
That authenticates the appearance of a lot of outliers, extreme values. That can be attributed to the income disparity in the community. Component of what can be motivated by the fact that we are seeing people with various education knowledge levels. Let us separate them through Education.

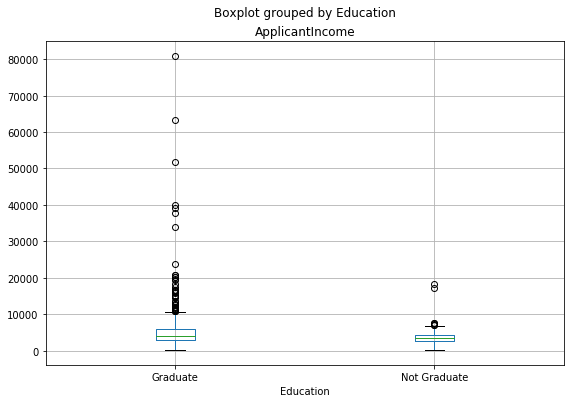
We can recognize that there is no real difference in the mean income of graduates furthermore non-graduates. Although there is a tremendous amount of graduates with extremely high incomes, which continue resembling to be the outliers.
Presently, Let’s see at the histogram and boxplot of LoanAmount applying the next command:
![]()
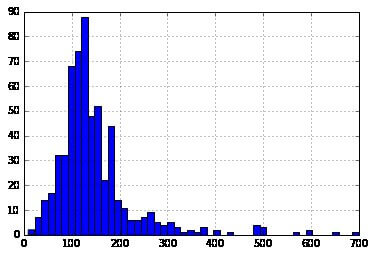
![]()
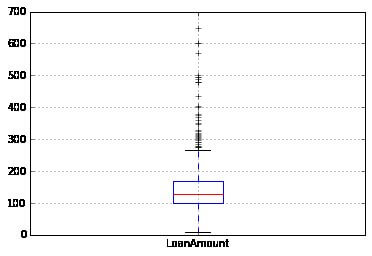
Repeatedly, there are any absolute values. Obviously, both ApplicantIncome and LoanAmount need some number of data munging. LoanAmount has avoided and quite as extreme values, while ApplicantIncome has several extreme values, which require more extensive understanding. We will take that up in the following sections.
Categorical Variable Analysis
Presently that we understand patterns for ApplicantIncome and LoanIncome, allow us to understand certain variables in more extra detail. the inclination to use an Excel-style swivel table and cross-tabulation. For example, let us see at the chance of acquiring a loan based on account records. That can be accomplished in MS Excel applying a pivot table.
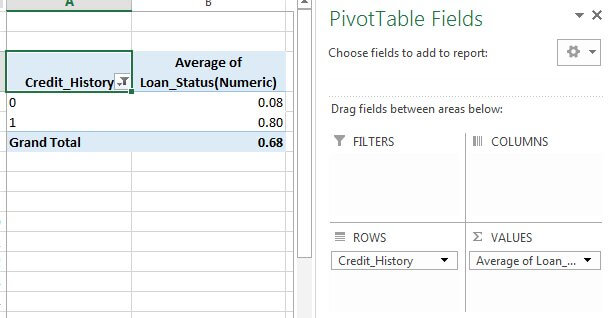
Reminder: here loan situation should be coded as 1 toward Yes and 0 for No. Then that means describes the possibility of getting a loan.
Presently we will see at the moves needed to create a comparable acumen using Python. Please apply to this section for getting a hang of the various data manipulation procedures in Pandas.


we can see that we make a similar pivot_table alike the MS Excel one. That can be plotted as a strip chart using the “Matplotlib” library with the following code:

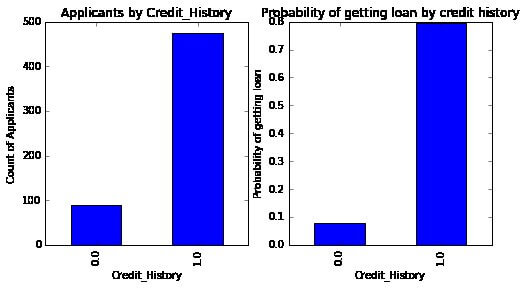
That shows that the possibility of getting credit is eight-fold if that applicant has a correct credit history. Then you can plot comparable graphs by Married, Self-Employee, Property_Area, etc.
Alternately, those two plots can further be reflected by combining them in a stacked chart.

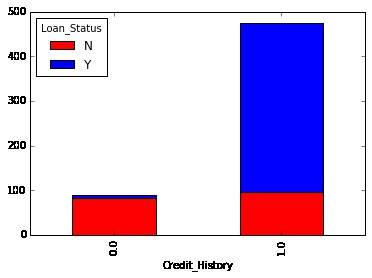
You can also add gender within the mix, similar to the pivot table in Excel.
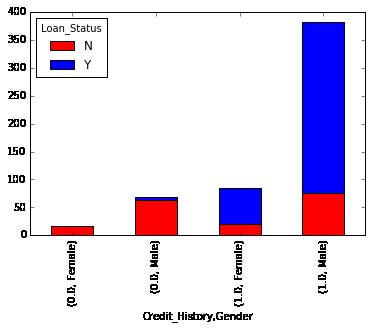
If you have not realized previously, we have just built two basic classification algorithms here, 1 based on credit history, while others at 2 certain variables, including gender. so now you can immediately code that to build your first submission toward AV Datahacks.
We just discussed wherewith we can do exploratory analysis in Python using Pandas. I trust your love for pandas the creature would have improved with now – given the quantity of help, the library can present you in analyzing datasets.
Following let’s examine ApplicantIncome and LoanStatus variables more, make data munging and build a dataset for using several modeling techniques. I would powerfully recommend that you use another dataset and query and run by a sovereign example before reading additional.
Data Munging Python Using Pandas
Concerning these, who must be following, here are you must use footwear to begin running.
Data munging a recap of the necessary
While our investigation of the data, we obtained some difficulties in the data set, which requires to be answered ere the data is available for a good model. That task is typically connected to “Data Munging”. Here are some problems, we are previously knowledgeable of
There are some missing values in any variable. We should expect these values sensibly depending on the number of missing values and the assumed value of variables. While watching at the distributions, we noticed that ApplicantIncome and LoanAmount appeared to hold absolute values at each end. Though they sway make inherent sense, but should be used properly.
In interest to those problems with digital fields, we should further look at the non-numerical areas i.e. Gender, Property_Area, Married, Education and Dependents to see, if they contain any valuable knowledge. If you are brand-new to Pandas, I would suggest viewing this section ere moving on. That details any helpful techniques of data manipulation.
Check The Missing Values In The Data Set
So let’s see the missing values in all variables because many models don’t work with missing data and even if they do, so the imputing help and more frequently than not. so let us find the number of nulls/ and NaNs in the dataset
df.apply(lambda x: sum(x.isnull()),axis=0)
So that command should be told we the number of missing values in every column as is null() returns if your value is null.
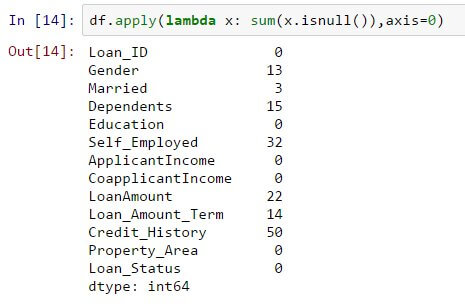
The missing values are not the very higher number, but many variables hold them and every one of the certain should be considered and attached with in the data. so got a details view of various imputation method’s by this content
So we get missing values may not always be NaNs. for instance, so if the loan amount is 0 then it makes sense or will you consider the missing values. I expect your answer is missing and you are correct. so we hold the values which are unpractical.
Fill Missing Values in Loan Ammount
Various ways to fulfill missing values of loan amount so the easiest being the replacement by mean which can be done by the next code:
df[‘LoanAmount’].fillna(df[‘LoanAmount’].mean(), inplace=True)
Extra extreme could be to develop a supervised learning model to predict loan amount on the base of another variable and next use age forward with other variables to predict survival.
So the goal now is to carry out the actions in data munging, then we will give a suggestion, in which lies wherever in between those 2 extremes. A solution to the hypothesis is that whether a character is trained and self-employed can connect to present a fabulous extreme to the loan amount.
so let’s view at the boxplot to look if any trend exists
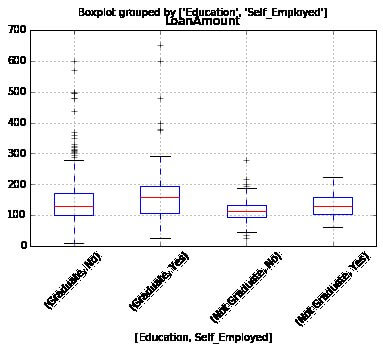
we look at any variations in the midpoint of the loan amount for all groups and such can be utilized to impute the values. Only first, we must secure this every of self-employed and educations variables should no have a missing values
So as we said earlier, self-employed has some missing values so let’s see on the frequency table.
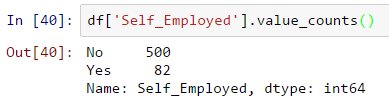
Since 85% value is No, this is saved to assign the missing values as “no” as there is a higher possibility of success. That can be arranged using the next code:
df[‘Self_Employed’].fillna(‘No’,inplace=True)
Now we create a pivot table in which provides us median values for whole the groups of different values of self-employed and education characteristics following we describe a function, which repeats the values of those cells and utilizes that to fulfill the missing values of the loan amount:

That provides you the best way to impute the missing values of the loan amount.
Those approaches will run just if you must not fill the missing values into the loan amount variable applying the previous procedures.
How to Handle for extreme values in the pattern of LoanAmount and ApplicantIncome?
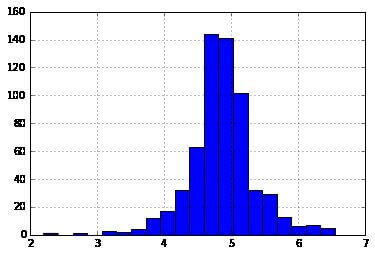
first of all, analyze the loan amount. The absolute values are practically possible, and some people may apply for higher-value loans due to specific requirements. So instead of handling them as outliers so let us try a long transform to nullify their impact.

Looking at histogram
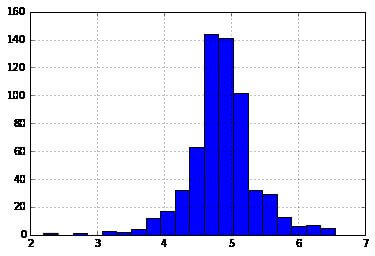
And now the distribution sees much closer to normal and the effect of extreme values has been significantly subsided.
Proceeding to candidate income. one inspiration can be that some candidates should low income yet powerfull support co-candidates. So this may be a great idea to connect both incomes as complete income and get a long transformation of the same.

See we will make a predictive model.
Model Predict Python
Later we made the data beneficial for modeling, allows now see at the python code to build a predicting model at our data set. Skit learn remains the most generally applied library in python for the goal and we will next to the trail. we support you to take a refresher on sklearn through that section.
sklearn needed all inputs to be numeric, we should furtive all our categorical variables within numeric by encoding the levels. Ere that, we will fulfill all the missing values in the dataset. This can be done by applying the next code.


Following, we will import the needed modules. Next, we will describe a general distribution function, which uses a model like a figure and determines the Precision and Cross-Validation rates. As that is an original section, we will not go inside the features of coding. Please connect to this section for obtaining specifications of the algorithms including R and Python codes. Moreover, that will be good to accept a refresher on cross-validation by its chapter, as that is a very considerable quantity of power performance.


Logistic Regression
makes our first logistic regression model. So here is one method to attach or use all variables inside the model but this is may result in overfitting. We all talking of all variables that may be effective in the model perception complex relationships special to the data and will not conclude well. Here is the link to learn more about logistics regression.
we can so simply perform some automatic hypotheses to insert the ball rolling. And the possibility of getting a loan will be higher.
- Candidates holding a credit history
- candidate with the higher applicant and co-applicant incomes.
- Candidates with a higher knowledge level
- Resources in urban areas with high growth perspectives
To make our first model with Credit_History.

This Accuracy Score is 80.945%
This Cross-Validation Score is 80.946%

This Accuracy Score is 80.945%
This Cross-Validation Score is 80.946%
Commonly, we assume the correctness to improve on attaching variables. Still, that is a major challenging case. The correctness and cross-validation scores are not getting struck by a few significant variables. Credit_History is managing the mode. We have two choices now.
Characteristic Engineering derives fresh information and attempts to predict these. I will move that to your creativity.
More solid modeling methods.
Decision Tree
The decision tree is an extra method for building a predictive model. This is understood to give higher exactitude than the logistic regression model. Learn further about Decision Trees.

That Accuracy is 81.930% That Cross-Validation Score is 76.656%
Here the model based on unconditional variables is incapable to have an impression because Credit History is dominating across them. Try some digital variables:

That Accuracy is 81.930% That Cross-Validation Score is 76.656%
Here we noted that although the correctness moved up on attaching variables, this cross-validation mistake let down. That is the outcome of model over-fitting that data. Try an even more advanced algorithm and understand if these benefits
Random-Forest
Random forest is a different algorithm for determining the classification problem. Study further about Random Forest.
An advantage with Random Forest is that we can execute that work beside all the characteristics furthermore this repeats a characteristic value matrix that can be applied to select characteristics.

Accuracy Score is 100.000%
cross-Validation Score is 78.179%
Here we look that the correctness is 100% for the training set. That is the latest case of overfitting and can be solved in two methods.
- Decreasing the number of predictors
- Harmonizing the design parameters
Try both of those. First, we look at the characteristic value matrix from which we will get the most valuable characteristics.

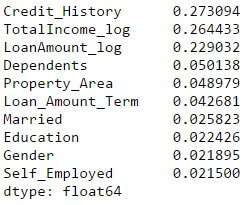
Use the top 5 variables for making a model. Also, we will adjust the parameters of the random forest model a small part.

Accuracy Score is 100.000%
Cross-Validation Score is 78.179%
Mark that although efficiency decreased, the cross-validation rate is increasingly showing that this model is concluding well. Recognise that random forest designs are not accurately repeatable. Various scores will result in small variations because of randomisation. But the output should visit in the ballpark.
You would be notice that too after any basic parameter attuning on random forest, we have arrived a cross-validation exactness only slightly more immeasurable than the initial logistic regression model. That lesson provides us some really interesting and unique knowledge.
Conclusion
I wish this tutorial will help you maximise your effectiveness when beginning with data science in Python. I am sure that not only provided you an opinion about basic data analysis techniques but that also gave you how to execute any of the more sophisticated methods available today. You should more verify out our frank Python course and suddenly jump over to learn how to apply That for Data Science.
Data science with python is truly an excellent tool and is growing an increasingly attractive language with data scientists. The object being, that’s easy to read, blends fine with other databases including tools like Spark and Hadoop. Majorly, this has a famous computational power and has the highest data analytics libraries.
So, read Python to complete the full biography-cycle of each data science project. That involves a presentation, analysing, visualising and definitely making predictions.
Then if you proceed crossed any trouble while functioning data science with python, or you hold any opinions /advice/feedback on this post, please touch-free to post them into explanations below.
So we can get a data science course and learn a full data science course. And data science course has many libraries and many functions so data science course is good for beginners. And the data science course is given in the link below.


